이것저것 시도해보다 처음에 Configure 할 때 옵션을 잘 못 넣은 것 같다. 64bit로 빌드할 때는 마지막 옵션에 mingw64를 써야하는데 mingw만 넣고 빌드한 것 같다. (사실 확실치는 않다. 컴파일러도 삭제하고 다시 설치해보고, 뭐 이것저것 했기 때문이다)
Block cipher의 AES를 FIPS문서대로 구현해보려고 한다. 사용언어는 C이고, 문서에 나와있는 pseudocode을 최대한 만족해서 작성할 것이다. 이렇게 해야 내가 나중에 이해하기 편할 듯 하다.
사실 문서의 내용들, 즉 이론을 리뷰하면서 글을 작성하려고 했는데, 너무 내용도 방대하거니와 생각보다 작성된 내용이 쉽게 해석이 되서 굳이 여기서 작성하지 않고 문서 자체를 보는게 이해하는데 훨씬 도움이 될 것 같다. 심지어 인터넷에 한글 또는 영문의 기가막힌 설명들이 너무 많다. 나도 해당 내용들을 참고해가며 구현했기에 굳이 여기서 허접한 영어 실력과 이해로 설명하고 싶진 않다.
먼저, FIPS 란
TheFederal Information Processing Standards(FIPS) of theUnited Statesare a set of publicly announcedstandardsthat theNational Institute of Standards and Technology(NIST) has developed for use in computer situs of non-military United States government agencies and contractors. -Wikipedia
미국 연방 정보 처리 표준 (FIPS)은 미국의 비군사 정부 기관 및 계약자가 사용하는 컴퓨터 시스템을 위해 국가 표준 기술 연구소 (NIST)가 개발한 공개 표준 세트입니다.
FIPS는 표준의 세트이다. 그러므로 여러 버전이 있다. 예를 들면 다음과 같다.
FIPS 140: Cryptographic Module Validation Program
FIPS 197: Advanced Encryption Standard
FIPS 180: Secure Hash Standard (SHS)
등등이 있다.
참고로 위 FIPS 140은 암호 모듈로서 개발된 소프트웨어나 하드웨어를 검증하는 프로그램이다. 흔히 FIPS 인증을 받았다고 한다면 위 FIPS 140으로 이해하면 된다. 현재 FIPS 140-3 버전이다.
Cipher 함수 외부에서는 KeyExpansion 으로 키를 확장한다. 확장된 키는 각각 w 배열에 저장되고 이를 Cipher 함수에서 사용한다. 먼저 Pseudo code 부터 살펴보자.
KeyExpansion
Key Expansion
C 코드는 다음과 같다.
void KeyExpansion(byte *key, word* w, int Nk)
{
int i = 0;
word temp;
while(i < Nk)
{
w[i] = ((key[4 * i] << 24) | (key[4 * i + 1] << 16) | (key[4 * i + 2] << 8) | key[4 * i + 3]);
i = i + 1;
}
i = Nk;
int Nr = 10;
while(i < Nb * (Nr + 1)) /* Total round = preRound + round */
{
temp = w[i - 1];
if((i % Nk) == 0)
{
temp = SubWord(RotWord(temp)) ^ Rcon[i / Nk];
}
else if((Nk > 6) && (i % Nk == 4))
{
temp = SubWord(temp);
}
else
{
// Do nothing
}
w[i] = w[i - Nk] ^ temp;
i = i + 1;
}
}
16, 24, 32bytes의 키를 각 키길이에 맞는 round 10, 12, 14의 횟수만큼 갯수를 늘리는게 KeyExpansion 역할이다. 단, round 전에 pre-round가 있기 때문에 실제 round 횟수는 각각 11, 13, 15이다.
RotWord와 SubWord는 각각 다음과 같다.
RotWord
RotWord()
아래 코드 주석에 나와있는대로, 1 word가 4바이트, 바이트 단위로 나눠봤을 때, [a0, a1, a2, a3] 각각 1바이트씩 총 4바이트다. 여기서 순서를 [a1, a2, a3, a0] 로 순환시키는게 RotWord다.
/* The function takes a RotWord() word [a0,a1,a2,a3] as input, performs a cyclic permutation,
* and returns the word [a1,a2,a3,a0]. */
word RotWord(word w)
{
w = (w >> 24) | (w << 8);
return w;
}
SubWord
SubWord()
/* is a function that takes a four-byte input word and applies the S-box (Sec. 5.1.1,
SubWord() Fig. 7) to each of the four bytes to produce an output word.*/
word SubWord(word w)
{
int idx = 0;
for(int i = 0; i < 4; i++)
{
w = ((SBOX[(w >> (24 - (8 * i))) & 0xFF]) << (24 - (8 * i))) | w & ~(0xFF << (24 - (8 * i)));
}
return w;
}
Rcon은 미리 정의되어 있는 값이다.
/* The round constant word array, Rcon[i], contains the values given by [x^(i-1),{00},{00},{00}],
with x^(i-1) being powers of x (x is denoted as {02}) in the field GF(28), as discussed in Sec. 4.2 (note that i starts at 1, not 0).*/
static const word Rcon[] = {
0x00000000, 0x01000000, 0x02000000, 0x04000000, 0x08000000,
0x10000000, 0x20000000, 0x40000000, 0x80000000,
0x1B000000, 0x36000000, /* for 128-bit blocks, Rijndael never uses more than 10 rcon values */
};
AddRoundKey
AddRoundKey
AddRoundKey는 각 round의 w와 state를 xor 하는 연산이다. 별거 없다. state의 첫번째 열부터 w의 첫번째 원소부터 각각 xor 을 반복하면 AddRoundKey가 된다.
/*
* 5.1.4 AddRoundKey() Transformation
* In the AddRoundKey() transformation, a Round Key is added to the State by a simple bitwise
XOR operation.
*/
void AddRoundKey(byte *state, const word *w)
{
int i, j;
for(i = 0; i < Nb; i++)
{
for(j = 0; j < Nb; j++)
{
state[(i * 4) + j] ^= (w[i] >> (24 - (8 * j))) & 0xFF;
}
}
}
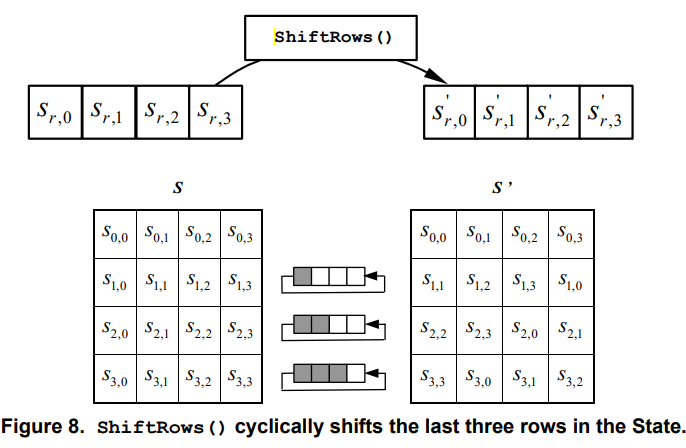
ShiftRows
각 행의 원소들을 순환하며 섞는다. ShiftRows 의 연산 방법은 아래 그림 하나로 모든게 설명된다.
ShiftRows
첫번째 행은 연산되지 않는다. 두번째 행부터 shift 연산을 한다. 2행의 첫번째 원소가 2행의 가장 끝으로 shift 된다. 3행은 앞의 두개 원소가 뒤의 2개 원소 뒤로 shift 되고, 4행은 마지막 원소가 가장 앞으로 shift 된다. 코드로 구현하면 다음과 같다.
/*
* 5.1.2 ShiftRows() Transformation
* In the ShiftRows() transformation, the bytes in the last three rows of the State are cyclically
shifted over different numbers of bytes (offsets). The first row, r = 0, is not shifted.
*/
void ShiftRows(byte *state)
{
word temp;
int i;
// Row 0 not changed
for(i = 1; i < 4; i++)
{
temp = (state[i] << 24) | (state[i + 4] << 16) | (state[i + 8] << 8) | (state[i + 12]);
temp = (temp >> (32 - (i * 8))) | (temp << (i * 8));
state[i] = (temp >> 24) & 0xFF;
state[i + 4] = (temp >> 16) & 0xFF;
state[i + 8] = (temp >> 8) & 0xFF;
state[i + 12] = (temp) & 0xFF;
}
}
MixColumns
이 함수가 구현하기 가장 까다롭지 않나 싶다. ShiftRows는 행을 섞었다면, MixColumns은 열의 값들을 섞는다. 이때, 사용되는 수학적 방법은 행렬의 곱셈이다. 아, 간만에 행렬의 곱, 역행렬, 단위행렬이란 단어를 보게 되네. 사실, 수학적 이론이 많이 가미되는 연산이라 구글링해서 찾아보는게 더 나을 듯 하다. 여기서는 구현된 코드만 작성한다.
지금까지 Cipher 함수를 구성하는 하위 함수들을 알아봤다. 이 함수들을 조합한 Cipher 함수로 블럭사이즈 128bits를 암호화할 수 있다. 간단한 벡터와 결과값은 해당 문서의 뒤쪽에 나와있다. 예를 들면, 아래와 같이 키 스케쥴부터 시작해서 ShiftRows, MixColumns 등의 단계별 출력값들이 작성되어 있다. 이 값들과 비교해가면서 Cipher와 하위 함수들을 구현해가면 된다.
InvCipher 는 문서에 나와있는 그대로 구현하면 어려울 건 없다. 다만, InvMixColumns 를 구현하는데 정말 애 먹었다. 일단, 구현 방법의 힌트는 다음과 같다.
𝑥 × 9 = (((𝑥 × 2) × 2) × 2) + 𝑥
𝑥 × 11 = ((((𝑥 × 2) × 2) + 𝑥) × 2) + 𝑥
𝑥 × 13=((((𝑥 × 2) + 𝑥) × 2) × 2) + 𝑥
x × 14 = ((((x × 2) + x) × 2) + x) × 2
여기서 𝑥 × 2 연산은 원소값을 2 곱한 값 (left shift 1) 과 원소의 msb가 1이라서 carry가 발생할 경우, 원소와 0x1b를 xor 한 값을 이전에 2 곱한 값과 xor 한다. 뭔가 장황한데, 수식으로 표현하면 이렇다.
(x << 1) ^ (((x >> 7) & 0x01) * 0x1b)
위의 연산을 9, 11, 13, 14를 곱할 때, 적용해서 하는거다.
처음에 저 연산을 macro 함수로 했다가, 값이 안나와서 몇일을 고생했다. 도대체 왜 안나오는거였는지 참...
InvColumns 만 잘 구현된다면 InvCipher도 쉽게 구현 가능하다.
쓰다 보니 너무 장황해지긴 했는데, 그래도 표준 문서에 최대한 근접하게 구현하려고 노력했다. 생각보다 표준문서에서 쉽게 구현할 수 있게 너무 자세하게 설명되어 있어서 놀랐다. 항상 이런 문서들을 보면서 느끼는거지만, 생각보다 표준문서에 설명이 잘 되어있고, 답이 있는 것 같다. 먼저 인터넷부터 뒤지고 학습하는 것보다 이런 표준문서를 보면서 기초부터 쌓아가는 것도 나이스한 것 간다.